Оптимизация виртуализации Win10 на qemu-kvm
Примечание: Описываемые действия применять на свой страх и риск. Автор не несёт ответственности за совершаемые вами действия и их последствия.
Примечание: Данная статья демонстрирует вариант оптимизации, который заметно увеличивает производительность в конкретном случае. Представленные результаты тестирования не претендуют на точность, их основная цель продемонстрировать наличие эффекта от применения описываемых оптимизаций.
Содержание.
- Программы для тестирования.
- Пример результатов тестирования без оптимизаций.
- Переключение процессора в режим производительности.
- Пример улучшения производительности.
- Пример настроенной конфигурации виртуальной машины.
- Отключение memballoon.
- Настройка дисковых устройств.
- Настройка SPICE.
- CPU Pinning — vcpupin.
- Настройка таймеров.
- Настройка hugepages (большие страницы).
Вступление.
Официальная документация по libvirt: https://libvirt.org/formatdomain.html
В предыдущей статье была рассмотрена базовая виртуализация Windows 10 и проброс видеокарты Nvidia GTX 1060: https://noostyche.ru/blog/2021/02/11/qemu-kvm-probros-videokarty-nvidia/
Windows 10 чрезвычайно тяжёлая ОС с множеством активных служб, вызывающих пилообразную нагрузку и огромное количество прерываний, поэтому без оптимизации работы виртуальной машины не обойтись.
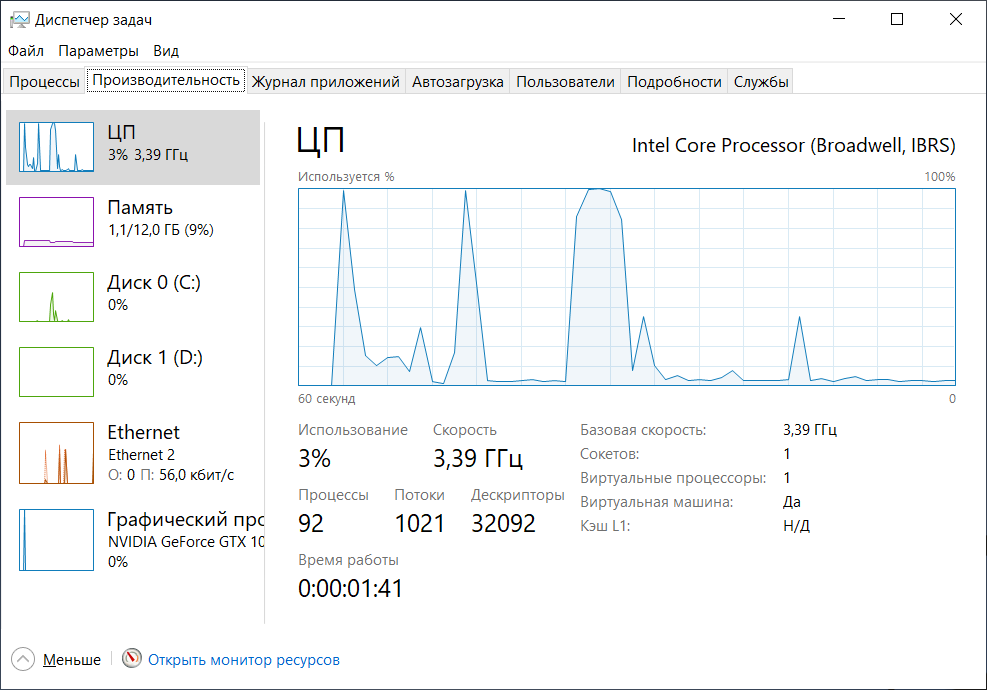
Программы для тестирования.
Данный нехитрый набор достаточен для оценки производительности гостевой ОС Windows.
- LatencyMon — предназначена для измерения задержек прерываний. Чем выше задержки, тем сильнее проявляются «заикания», включая потрескивание звука.
- Cinebench — тестирование производительности процессора.
- Unigine Superposition Benchmark — тестирование 3D производительности.
- Unigine Valley — тестирование 3D производительности.
Пример результатов тестирования без оптимизации.
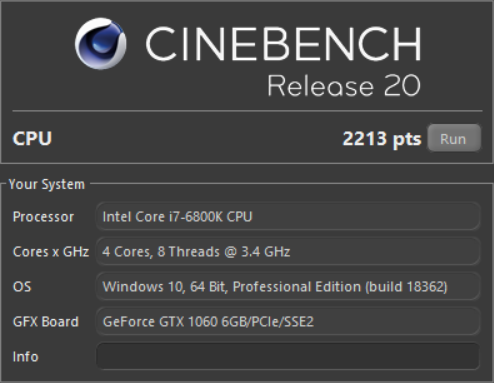
Cinebench.
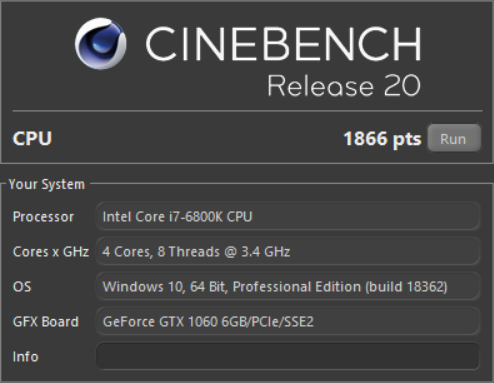
После оптимизации результат улучшится на ~15%.
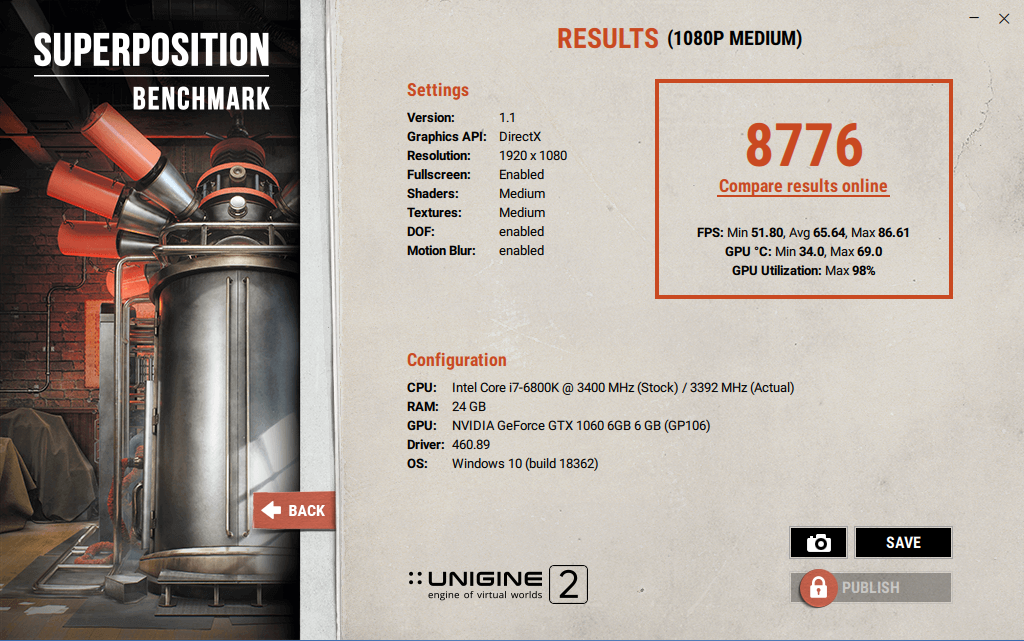
Unigine Superposition.

После оптимизации результат улучшится на ~2%.
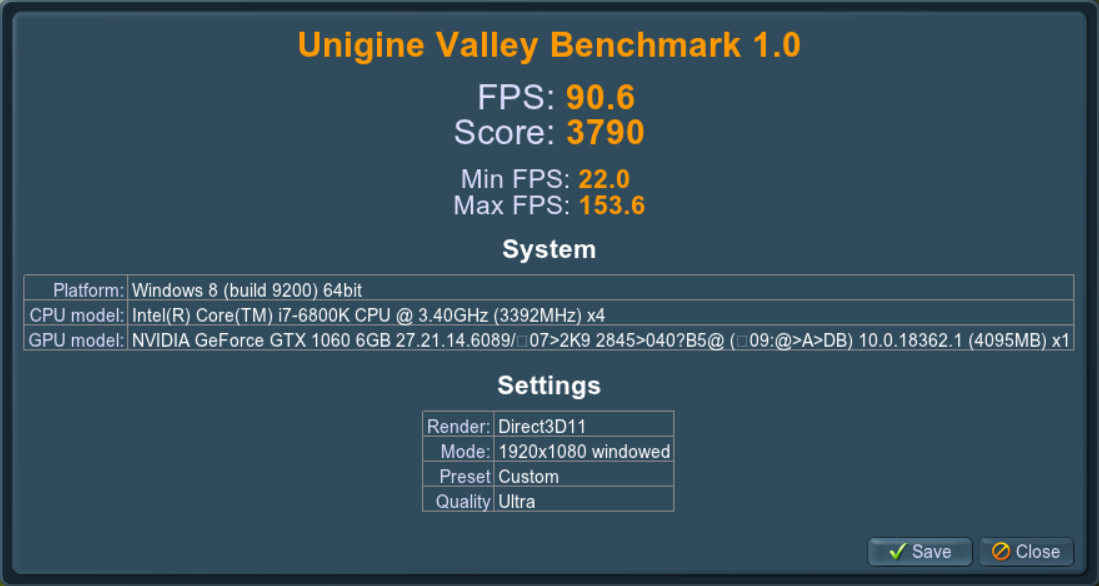
Unigine Valley.
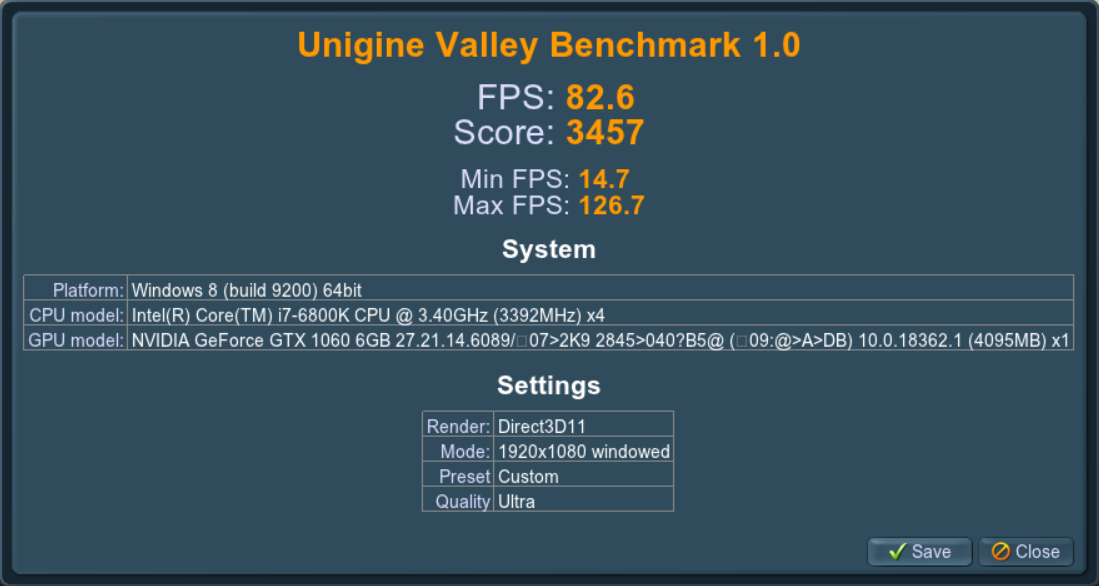
После оптимизации результат улучшится на ~10%.
Переключение процессора в режим производительности.
Особенностью виртуализации с помощью qemu-kvm является то, что гостевая ОС не может управлять частотой процессора, ей управляет CPU frequency scaling хоста. CPU frequency scaling имеет несколько режимов (governors) управления частотой процессора. Если на хосте используется режим энергосбережения (powersave), то высокие нагрузки в гостевой ОС приведут к возникновению больших задержек прерываний (interrupts latency), проявляющихся в виде «заиканий», включая треск при проигрывании звука. Подобные проблемы могут быть и на сбалансированном режиме работы — ondemand или schedutil. Это особенно явно проявляется в виртуальной машине с Windows 10 даже при «щадящей» эксплуатации. В Linux-госте проблема хорошо заметна при проигрывании видео, особенно в полноэкранном режиме — воспроизведение будет с рывками. Решением является переключение на режим производительности — performance.
Зашкаливающие задержки прерываний выглядят подобным образом:

По моим наблюдениям, именно энергоэффективный режим работы процессора является ключевым источником проблем с производительностью и отзывчивостью виртуальной машины.
Настройка режима производительности процессора.
Потребуется переключить режим управления частотой процессора на performance. Тем самым хост будет предоставлять максимум производительности для виртуальной машины.
Вывести доступные режимы:
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_available_governors | tail -n 1
В выводе будет подобное:
conservative ondemand userspace powersave performance schedutil
Проверить режим работы процессора:
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
Скорее всего, в выводе будет ondemand — сбалансированный режим. Его необходимо переключить на режим performance.
Переключение можно осуществить следующей командой:
sudo echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
Вот и всё. С performance в гостевой ОС не будет заиканий и треска при проигрывании звука.
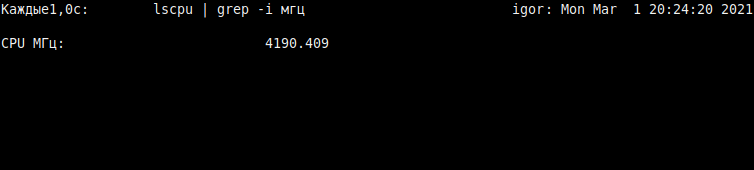
Можно убедиться, что под нагрузкой процессор работает «на максимум», сделав вывод значения частоты с обновлением раз в секунду:
watch -n1 'lscpu | grep -i МГц'
Примечание: «Мгц» будут только с русифицированным интерфейсом. В англоязычном — «MHz».
Важный нюанс для Ubuntu.
На момент 2021 года в Ubuntu и её деривативах всё ещё присутствует демон ondemand, который не следует путать с режимом управления частотой процессора. В стародавние времена он служил для динамичного управления энергосбережением, а ныне в нём нет надобности. Если этот демон включён, то после перезагрузки хоста вновь будет включен режим ondemand, а не ранее включенный performance.
Стоит проверить активен ли демон ondemand:
service ondemand status
Если выключен, то вывод будет таким:
ondemand.service - Set the CPU Frequency Scaling governor Loaded: loaded (/lib/systemd/system/ondemand.service; disabled; vendor pre> Active: inactive (dead)
Если включен, то потребуется отключить следующим образом:
sudo systemctl disable ondemand
После этого режим performance не будет переключаться на ondemand после перезагрузки.
Предварительный результат улучшения производительности.
Только за счёт переключения режима управления частотой процессора удалось получить более 15% к производительности ядер для виртуальной машины:
Для 3D графики результат скромнее, но эффект хорошо заметен.
Было: 8695 очков. Стало: 8776.
Было: 3457. Стало: 3790.
Пример настроенной конфигурации.
Примечание: Представленную конфигурацию недопустимо копировать «как есть», так как ряд строк специфичны для конкретной конфигурации оборудования.
<domain type="kvm">
<name>win10</name>
<uuid>12207adt-120b-42c8-835b-a8b6129g47b7</uuid>
<metadata>
<libosinfo:libosinfo xmlns:libosinfo="http://libosinfo.org/xmlns/libvirt/domain/1.0">
<libosinfo:os id="http://microsoft.com/win/10"/>
</libosinfo:libosinfo>
</metadata>
<memory unit="KiB">12582912</memory>
<currentMemory unit="KiB">12582912</currentMemory>
<memoryBacking>
<hugepages>
<page size="2048" unit="KiB"/>
</hugepages>
<nosharepages/>
<locked/>
<discard/>
</memoryBacking>
<vcpu placement="static">6</vcpu>
<cputune>
<vcpupin vcpu="0" cpuset="2,8"/>
<vcpupin vcpu="1" cpuset="3,9"/>
<vcpupin vcpu="2" cpuset="4,10"/>
<vcpupin vcpu="3" cpuset="5,11"/>
<vcpupin vcpu="4" cpuset="2,8"/>
<vcpupin vcpu="5" cpuset="3,9"/>
<vcpupin vcpu="6" cpuset="4,10"/>
<vcpupin vcpu="7" cpuset="5,11"/>
<emulatorpin cpuset="0-1,6-7""/>
<vcpusched vcpus="0" scheduler="fifo" priority="1"/>
<vcpusched vcpus="1" scheduler="fifo" priority="1"/>
<vcpusched vcpus="2" scheduler="fifo" priority="1"/>
<vcpusched vcpus="3" scheduler="fifo" priority="1"/>
<vcpusched vcpus="4" scheduler="fifo" priority="1"/>
<vcpusched vcpus="5" scheduler="fifo" priority="1"/>
<vcpusched vcpus="6" scheduler="fifo" priority="1"/>
<vcpusched vcpus="7" scheduler="fifo" priority="1"/>
</cputune>
<os>
<type arch="x86_64" machine="pc-q35-4.2">hvm</type>
<loader readonly="yes" type="pflash">/usr/share/OVMF/OVMF_CODE.fd</loader>
<nvram>/var/lib/libvirt/qemu/nvram/win10_VARS.fd</nvram>
<boot dev="hd"/>
</os>
<features>
<acpi/>
<apic/>
<hyperv>
<relaxed state="on"/>
<vapic state="on"/>
<spinlocks state="on" retries="8191"/>
<vendor_id state="on" value="FckYouNVIDIA"/>
</hyperv>
<kvm>
<hidden state="on"/>
</kvm>
<vmport state="off"/>
</features>
<cpu mode="host-passthrough" check="none">
<topology sockets="1" cores="4" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="invtsc"/>
<feature policy="disable" name="hypervisor"/>
</cpu>
<clock offset="localtime">
<timer name="rtc" tickpolicy="catchup"/>
<timer name="pit" tickpolicy="delay"/>
<timer name="hpet" present="no"/>
<timer name="hypervclock" present="no"/>
<timer name="tsc" present="yes" mode="native"/>
</clock>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>destroy</on_crash>
<pm>
<suspend-to-mem enabled="no"/>
<suspend-to-disk enabled="no"/>
</pm>
<devices>
... Пропущены блоки устройств, чтобы не раздувать и без того большой объём текста
<graphics type="spice">
<listen type="none"/>
<image compression="off"/>
<jpeg compression="never"/>
<zlib compression="never"/>
<playback compression="off"/>
<streaming mode="off"/>
</graphics>
...
<memballoon model="none"/>
</devices>
</domain>
Отключение memballoon.
По конфигурации начнём с конца и по совместительству самого простого.
Memballoon — специальный драйвер, который обеспечивает подкачку памяти для гостевой ОС, если исчерпывается выделенная память.
Для поддержки memballoon в Win10 нужен специальный драйвер, который лишний раз укажет на факт виртуализации, который так старательно маскировали в предыдущей статье. Ко всему прочему драйвер ранее вызывал проблемы при совместном использовании с vfio, служащего для проброса видеокарты. Поэтому оптимальнее выключить.
Отключение осуществляется через редактирования конфигурации виртуальной машины. Конфигурация membaloon находится в блоке devices:
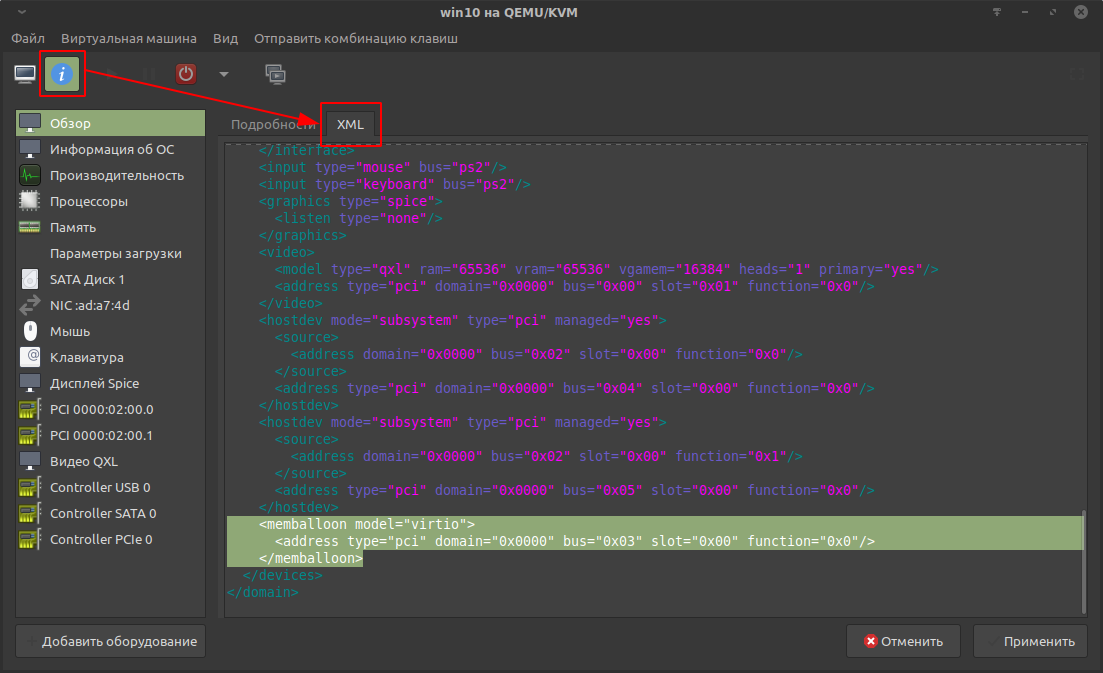
По умолчанию блок с memballoon выглядит подобным образом:
<memballoon model="virtio"><address type="pci" domain="0x0000" bus="0x03" slot="0x00" function="0x0"/></memballoon>
Блок с выключенным memballoon выглядит так:
<memballoon model="none"/>
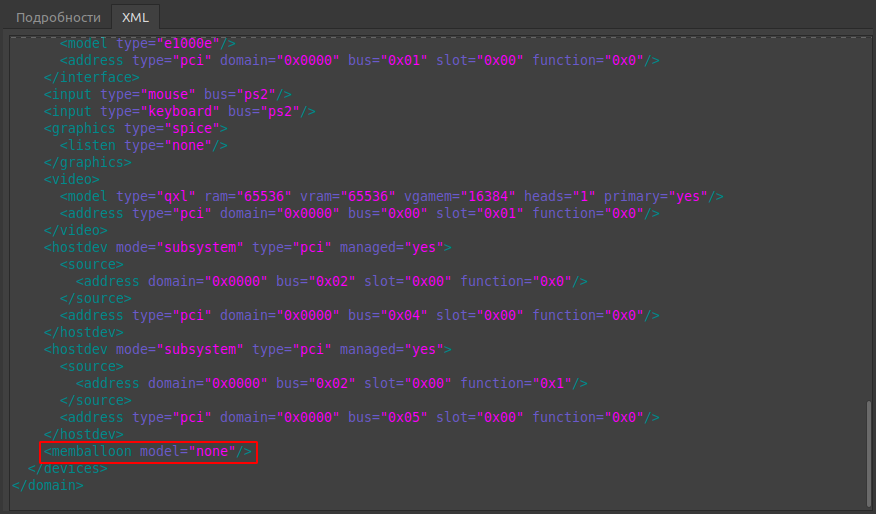
На этом по memballoon всё.
Настройка дисковых устройств.
Конфигурация дисковых устройств находится в блоке devices.
Пример настроенной конфигурации:
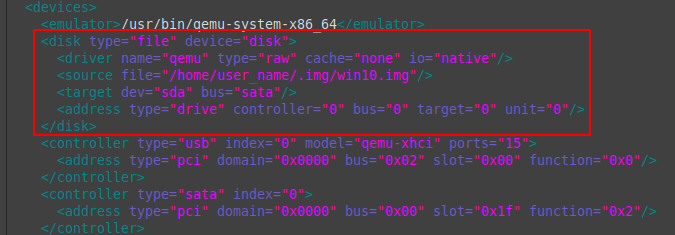
<disk type="file" device="disk"> <driver name="qemu" type="raw" cache="none" io="native"/> <source file="/home/user_name/.img/win10.img"/> <target dev="sda" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="0"/> </disk>
Разбор первой строки:
disk type = «file» device = «disk» — указывается, что виртуальный диск (блочное устройство) является файлом, а не физическим устройством.
Разбор второй строки:
driver name = «qemu» — название драйвера. По умолчанию qemu.
type = «raw» — тип виртуального диска (блочного устройства). У raw-образов оптимальная производительность. Подробнее в документации.
cache = «none» io = «native» — отключение кэширования и переключение режима ввода-вывода на native значительно улучшают производительность виртуального диска. Гостевая ОС будет заметно более отзывчивой.
Разбор третьей строки:
source file = «/home/user_name/.img/win10.img» — путь до файла образа виртуального диска.
Разбор четвёртой строки:
target dev = «sda» bus = «sata» — id виртуального диска и тип драйвера шины диска. SATA самый простой вариант для Windows-гостей, не требующий установки дополнительного драйвера, но наиболее быстрым является VirtIO. Его потребуется установить в гостевую ОС вручную со специального образа с набором драйверов и инструментов. Установка требует специфических манипуляций с гостевой ОС, поэтому этот вариант в данной статье не рассматривается.
В пятой строке оптимальны значения по умолчанию.
Настройка SPICE.
В предыдущей статье для управления виртуальной машиной был выбран протокол SPICE. В данном случае виртуальная машина запускается на локальном компьютере, а по умолчанию конфигурация SPICE больше рассчитана для удалённого доступа. Поэтому следует настроить для локального применения.
По умолчанию конфигурация выглядит подобным образом:
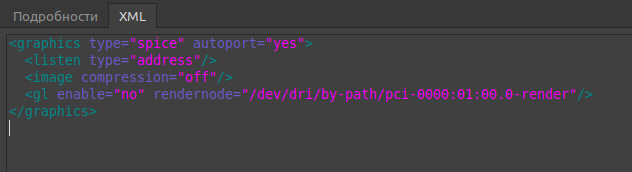
Отключение прослушки сети и сжатия пакетов заметно снижает уровень задержек. Оптимизированная конфигурация выглядит так:
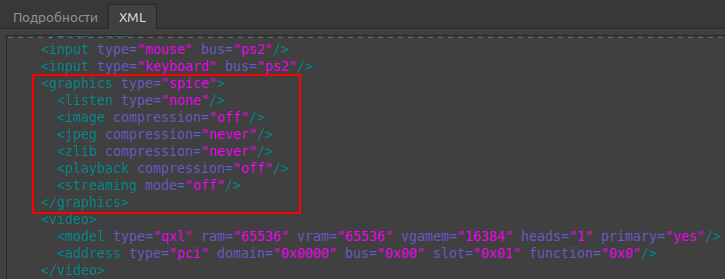
<devices> ...<graphics type='spice'><listen type='none'/><image compression='off'/><jpeg compression='never'/><zlib compression='never'/><playback compression='off'/><streaming mode='off'/></graphics>... </devices>
CPU Pinning — vcpupin.
Официальная документация: https://libvirt.org/formatdomain.html#cpu-tuning
Это прикрепление (pinning) потоков физического процессора к логическим ядрам виртуальной машины (vcpu). Благодаря прикреплению, обработка процессов виртуальной машины будет иметь несколько более высокий приоритет, что заметно снизит задержки прерываний. По умолчанию нагрузка логических ядер виртуальной машины распределяется между всеми потоками физического процессора. В виду того, что системе необходимо налету балансировать распределение ресурсов процессора между хостом и виртуальной машиной, время задержек прерываний для ряда задач может быть не оптимальным. Если наблюдается недостаточная отзывчивость гостевой ОС и проявляется потрескивание (заикание) звука, то стоит попробовать прикрепить потоки к логическим ядрам виртуальной машины.
Структура потоков процессора.
Перед прикреплением потоков к виртуальной машине необходимо ознакомиться со структурой логических ядер (потоков) физического процессора. У Intel и AMD она различается. В данном примере будет рассмотрен вариант с Intel.
Со структурой можно ознакомиться при выводе возможностей хоста с помощью утилиты virsh:
virsh capabilities
Будет отображён большой вывод с xml-структурой. В нём показаны возможности хоста в той же компоновке, как в xml-конфигурации виртуальной машины. Пример части вывода для системы с процессором Intel i7 6800K (12 логических ядер):
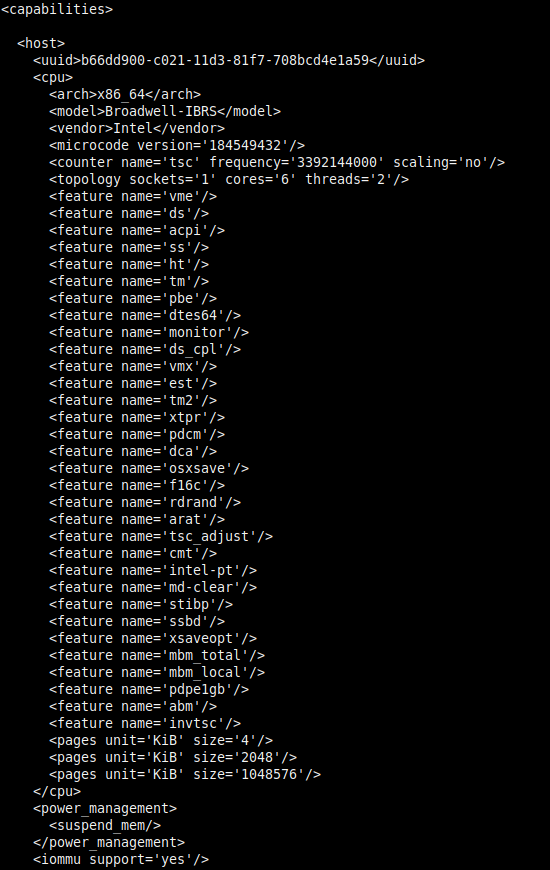
Информация о структуре потоков находится в блоке <cpus>:
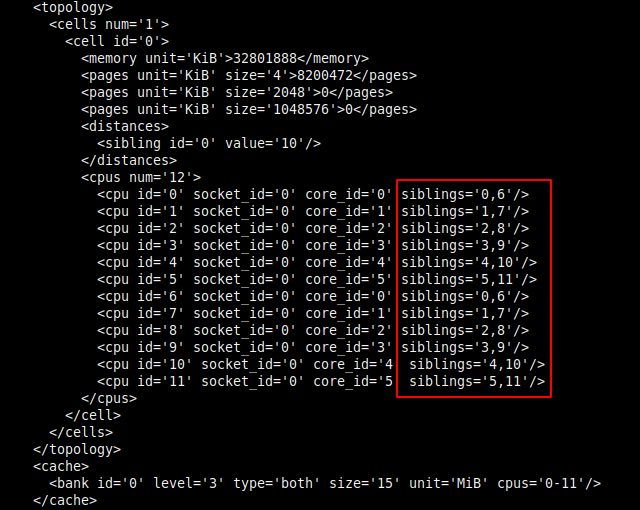
В современных процессорах используется технология гиперпоточности. Её особенностью является то, что одно физическое ядро предстаёт в виде двух логических ядер (потоков), что позволяет распределить вычислительную нагрузку более оптимально.
В данной статье в качестве примера рассматривается Intel i7 6800K с шестью физическими ядрами, что с гиперпоточностью даёт двенадцать логических ядер (потоков). Каждое логическое ядро относится к конкретному физическому ядру. Отсчёт логических ядер начинается от 0.
Из иллюстрации следует, что для шести физических ядер (core_id) используется двенадцать логических ядер (cpu id), тем самым каждому физическому ядру родственны по два потока:
- Логическое ядро cpu id=0 относится к первому физическому ядру core_id=0, которому принадлежат потоки 0 и 6.
- Второе логическое cpu id=1 к физическому core_id=1 с потоками 1 и 7.
- Третье cpu id=2 — core_id=2 с потоками 2 и 8.
- Четвёртое cpu id=3 — core_id=3 с потоками 3 и 9.
- Пятое cpu id=4 — core_id=4 с потоками 4 и 10.
- Шестое core_id=05 — core_id=5 с потоками 5 и 11.
- Седьмое логическое ядро cpu id=6 снова относится к первому физическому ядру core_id=0 с теми же родственными потоками — 0 и 6. Далее аналогично.
- Восьмое core_id=7 — ко второму core_id=1.
- Девятое core_id=8 — к третьему core_id=2.
- Десятое core_id=9 — к четвёртому core_id=3.
- Одинадцатое core_id=10 — к пятому core_id=4.
- Двенадцатое core_id=11 — к шестому core_id=5.
Выглядит причудливо, но разобраться можно.
Примечание: Структура потоков у Intel и AMD отличается. У AMD они идут один за другим. Пример: первое физическое ядро — потоки 0 и 1; второе ядро — 2 и 3 и так далее.
Так же структуру потоков можно вывести следующей командой:
lscpu -e
Пример вывода:
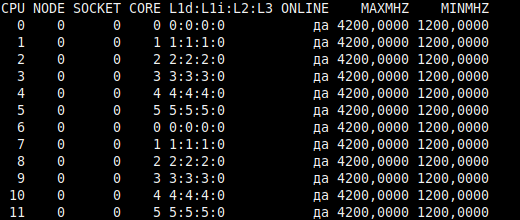
- Столбец CPU — перечислены номера (id) логических ядер. Отсчёт от 0.
- CORE — номера физических ядер, к которым относятся логические ядра. В виду того, что на одно физическое ядро приходится два логических ядра (потока), номер (id) в столбце повторяется.
Субъективно, такой вывод существенно менее очевиден, поэтому рекомендую первый метод.
Прикрепление потоков к виртуальным логическим ядрам виртуальной машины.
Прикреплённые потоки процессора не становятся изолированными для использования хост-системой. По умолчанию для логических ядер виртуальной машины (vcpu) задействованы все потоки хоста.
Для 8 логических ядер виртуальной машины это выглядит так:
<cputune><vcpupin vcpu="0" cpuset="0-11"/><vcpupin vcpu="1" cpuset="0-11"/><vcpupin vcpu="2" cpuset="0-11"/><vcpupin vcpu="3" cpuset="0-11"/><vcpupin vcpu="4" cpuset="0-11"/><vcpupin vcpu="5" cpuset="0-11"/><vcpupin vcpu="6" cpuset="0-11"/><vcpupin vcpu="7" cpuset="</cputune>0-11"/>
Для снижение задержек прерываний рекомендуют оставить в пользу хоста первое физическое ядро с его двумя потоками, так как оно нагружено различными программами, выполняемыми в хост-системе.
Примечание: В старых версиях qemu-kvm для Windows-гостей рекомендовалось обратное — прикреплять потоки от начала. Это было связано с программными недоработками, приводившими к сильному падению производительности виртуальной машины с Windows. Но в поздних версиях qemu-kvm эта проблема устранена.
В данном случае рассмотрен вариант, в котором для хост-системы оставлено четыре потока:
- Первое физическое ядро: 0 и 6.
- Второе физическое ядро: 1 и 7.
Да, из-за сокращения числа задействованных потоков производительность будет несколько ниже, но в данном случае целью является снижение задержек прерываний.
Первые четыре потока двух физических ядер можно задействовать для эмулятора qemu (emulatorpin), чтобы его работа не занимала процессорное время ядер, прикреплённых к виртуальной машине. Подробности далее.
Прикрепление осуществляется в блоке cputune. Настроенная конфигурация выглядит так:
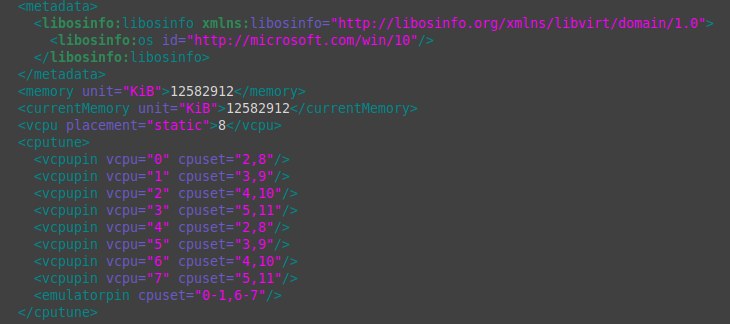
<cputune><vcpupin vcpu="0" cpuset="2,8"/><vcpupin vcpu="1" cpuset="3,9"/><vcpupin vcpu="2" cpuset="4,10"/><vcpupin vcpu="3" cpuset="5,11"/><vcpupin vcpu="4" cpuset="2,8"/><vcpupin vcpu="5" cpuset="3,9"/><vcpupin vcpu="6" cpuset="4,10"/><vcpupin vcpu="7" cpuset="5,11"/><emulatorpin cpuset="0-1,6-7""/> </cputune>
Возвращаемся к структуре потоков процессора Intel:
- Первое физическое ядро: 0 и 6.
- Второе: 1 и 7.
- Третье: 2 и 8.
- Четвёртое: 3 и 9.
- Пятое: 4 и 10.
- Шестое: 5 и 11.
В данном примере для виртуальной машины выделено 8 потоков из 12.
vcpupin vcpu = «0» — это первое логическое ядро виртуальной машины. Отсчёт ведётся от 0.
cpuset = «2,8» — здесь указывается номер потоков процессора, которые будут прикреплёны к логическому ядру виртуальной машины. Опираясь на вывод virsh capabilities, следует повторить аналогичную структуру прикрепления потоков, но уже к логическим ядрам виртуальной машины. В данном случае прикрепляются родственные потоки 2 и 8, принадлежащие третьему физическому ядру, так как условились, что потоки первого (0 и 6) и второго физических ядер (1 и 7) будут оставлены в пользу хоста.
vcpupin vcpu = «2» cpuset = «3,9» — второе логическое ядро виртуальной машины, к которому прикрепляются потоки четвёртого физического ядра 3 и 9.
Далее по аналогии.
emulatorpin cpuset = «0-1,6-7» — к эмулятору qemu прикрепляются потоки первого (0 и 6) и второго (1 и 7) физических ядер, которые не были прикреплены к логическим ядрам виртуальной машины. Тем самым эмулятор без крайней необходимости не будет использовать потоки, которые прикреплены к виртуальной машине, что позитивно скажется на снижении задержек прерываний. В целом это не обязательная опция.
Примечание: О записи номеров потоков. Отдельные потоки указываются через запятую, а группа потоков от одного до другого — через дефис. В данном случае парсер конфигурации автоматически «поправил» запись, что сделало её несколько причудливой, но на работу это не влияет.
На этом заканчивается самое соновное о прикреплении потоков физического процессора к логическим ядрам виртуальной машины.
Аппендикс об iothread.
В ряде публикаций можно увидеть прикрепление потоков для iothread. Это обработчик ввода-вывода для накопителей. В данном случае используется драйвер SATA, а iothread работает только с драйверами virtio-scsi и virtio-blk, поэтому в нём нет нужды.
Настройка планировщика.
Ещё одним вариантом снижения задержек прерываний является переключение режима планировщика на обработку процессов в реальном времени (режим «мягкого» реального времени). Планировщик предназначен для равномерного распределения вычислительной нагрузки на процессор с минимальными задержками. Информация для ознакомления:
- https://www.opennet.ru/man.shtml?category=2&russian=0&topic=sched_setscheduler
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/performance_tuning_guide/s-cpu-scheduler
Предпочтительным является режим FIFO (First In-First Out). Сразу стоит оговориться, что для ряда задач это может наоборот ухудшить время задержек прерываний, поэтому следует применять с осторожностью.
Настроенный вариант выглядит так:
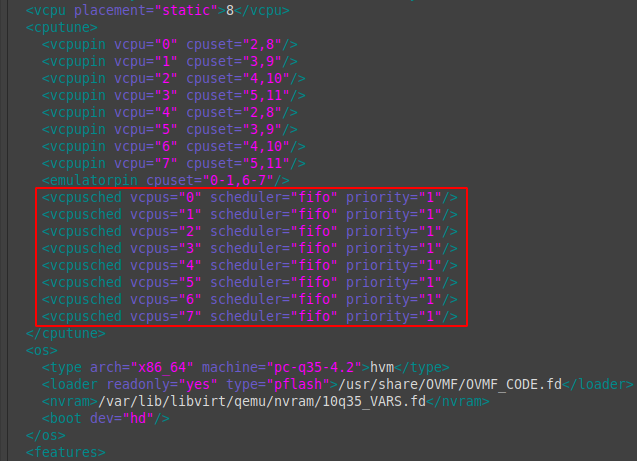
<cputune> ...<vcpusched vcpus="0" scheduler="fifo" priority="1"/><vcpusched vcpus="1" scheduler="fifo" priority="1"/><vcpusched vcpus="2" scheduler="fifo" priority="1"/><vcpusched vcpus="3" scheduler="fifo" priority="1"/><vcpusched vcpus="4" scheduler="fifo" priority="1"/><vcpusched vcpus="5" scheduler="fifo" priority="1"/><vcpusched vcpus="6" scheduler="fifo" priority="1"/><vcpusched vcpus="7" scheduler="fifo" priority="1"/></cputune>
scheduler = «fifo» — режим планировщика. Требуется указать для каждого логического ядра виртуальной машины.
priority = «1» — приоритет. Значения от 1 до 99.
Настройка таймеров.
Ознакомительный материал:
В документации обозначено, что для Windows-гостей оптимален таймер hypervclock, но в ряде публикаций в целях улучшения производительности, Windows 10 в особенности, настоятельно рекомендуется использовать tsc localtime и отключить «лишние» таймеры гипервизора, которые используются для калибровки.
По умолчанию блок с таймерами имеет подобный вид:
<clock offset="localtime"> <timer name="rtc" tickpolicy="catchup"/> <timer name="pit" tickpolicy="delay"/> <timer name="hpet" present="no"/> <timer name="hypervclock" present="yes"/> </clock>
Настройка.
Вывести доступные для использования системные таймеры:
cat /sys/devices/system/clocksource/clocksource0/available_clocksource
В выводе будет подобное: tsc hpet acpi_pm
Проверить какой таймер используется хостом:
cat /sys/devices/system/clocksource/clocksource0/current_clocksource
В выводе будет tsc.
Настроенный вариант имеет следующий вид:
<clock offset="localtime"> <timer name="rtc" tickpolicy="catchup"/> <timer name="pit" tickpolicy="delay"/> <timer name="hpet" present="no"/> <timer name="kvmclock" present="no"/> <timer name="hypervclock" present="no"/> <timer name="tsc" present="yes" mode="native"/> </clock>
Добавлены следующие строки:
timer name = «kvmclock» present = «no» — отключение таймера гипервизора kvm.
timer name = «hypervclock» present = «no» — отключение таймера hypervclock, но можно оставить включённым. В этом случае таймер будет использоваться для калибровки.
timer name = «tsc» present = «yes» mode = «native» — использовать проброс таймера tsc.
По таймерам почти всё, остаётся ещё один момент.
В блок <cpu></cpu> необходимо добавить строку feature policy = «require» name = «invtsc»:
<cpu mode="host-passthrough" check="none">
<topology sockets="1" cores="4" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="invtsc"/>
<feature policy="disable" name="hypervisor"/>
</cpu>Настройка hugepages.
Официальная документация: https://libvirt.org/formatdomain.html#elementsMemoryBacking
Теория:
Использование больших страниц для задач с интенсивной нагрузкой на оперативную память заметно улучшает производительность. Ключевым нюансом является то, что зарезервированная память будет изъята для использования хост-системой, поэтому крайне важно удостовериться, что оставшейся памяти достаточно для работоспособности.
Перед началом настройки стоит убедиться, что выделение больших страниц включено на уровне ядра:
grep HUGETLB /boot/config-$(uname -r)
Вывод:
CONFIG_HUGETLBFS=yCONFIG_HUGETLB_PAGE=y
Настройка конфигурации.
<memoryBacking>
<hugepages>
<page size="2048" unit="KiB"/>
</hugepages>
<nosharepages/>
<locked/>
<discard/>
</memoryBacking>page size = «2048» unit = «KiB» — размер страницы. Оптимальным считается 2 Мб, а для специфических задач, которые задействуют сотни гигабайт ОЗУ, используют страницы по 1 Гб.
nosharepages — не распределять выделенные страницы в пользу других запущенных виртуальных машин.
locked — страницы, выделенные в пользу виртуальной машины, будут заблокированы для использования хостом. Чтобы вернуть память хосту, потребуется завершить работу виртуальной машины. Опция полезна для задач, выполняемых в режиме мягкого реального времени (требующих минимальных задержек прерываний).
Динамичное выделение больших страниц.
Позволяет выделять и освобождать страницы памяти на ходу, что очень полезно, если виртуальная машина используется периодически, а не регулярно.
К примеру, время от времени требуется запустить виртуальную машину, выполнить некие задачи и завершить её работу. В случае статичного выделения страниц, память не будет доступна для хоста, а с динамичным выделением можно освободить все ранее выделенные страницы, но есть важный нюанс.
Основной проблемой динамичного выделения больших страниц в том, что нет гарантии выделения всех запрашиваемых страниц из-за фрагментации памяти (грязные страницы). Большие страницы должны быть выделены последовательно, если память сильно фрагментирована, то доступных последовательных блоков будет мало и все запрашиваемые страницы могут не выделиться. Если на хосте программы активно задействовали значительные объёмы памяти, то останется много грязных страниц (страничного кэша), которые «не позволят» выделить значительное число больших страниц.
Проблема может проявляться с выделением страниц объёмом на половину и более доступной памяти. Пример: всего 32 Гб, требуется выделить 8192 страницы по 2 Мб, но по факту система сможет выделить немногим более 6000.
Поэтому, если требуется гарантированное выделение страниц, его нужно осуществлять при старте системы, когда ещё нет фрагментации памяти. Такое выделение называется статичным, но о нём позже.
Проблему динамичного выделения больших страниц можно снизить следующими способами:
- Синхронизировать и сбросить страничный кэш, тем самым снизив фрагметацию.
- Попытаться выделить больше страниц, чем требуется по факту. Тем самым система будет агрессивнее выделять память, предоставив больше страниц.
Пример выделения динамичных больших страниц с синхронизацией и сбросом кэша.
Синхронизировать и сбросить кэшированные записи на накопитель:
sync
Сбросить Page Cache, Dentry и Inode cache, что позволит выделить больше оперативной памяти в виде больших страниц:
sudo echo 3 > /proc/sys/vm/drop_caches
Это не деструктивная операция. Будет сброшено лишь то, что не используется.
Скомпоновать память таким образом, чтобы свободная память была в смежных блоках, что снижает фрагментацию и позволяет выделить больше страниц:
sudo echo 1 > /proc/sys/vm/compact_memory
Выделить 8192 страницы по 2 Мб, чтобы задействовать 16 Гб ОЗУ в пользу виртуальной машины:
sudo sysctl vm.nr_hugepages=8192
Проверить сколько страниц было выделено фактически:
grep 'Huge' /proc/meminfo
Если страниц выделилось недостаточно, то придётся снизить количество памяти для виртуальной машины или перезагрузить хост-систему, что ликвидирует преимущества выделения «на ходу», и попытаться снова.
Статичное выделение больших страниц.
Чтобы избежать проблемы с не выделением всех запрашиваемых больших страниц из-за фрагментации памяти, их можно гарантированно выделить при старте хост-системы.
Выделение осуществляется через передачу значения специальному параметру ядра. Передать значение на старте системы можно посредством Grub. Для этого потребуется внести изменения в файл /etc/default/grub.
Необходимо добавить в строку GRUB_CMDLINE_LINUX_DEFAULT параметр hugepages=8192. Пример:
GRUB_CMDLINE_LINUX_DEFAULT="hugepages=8192"
Затем обновить конфигурацию Grub:
sudo update-grub
Тем самым после перезагрузки системы будет выделено 8192 страницы по 2 Мб, что по итогу зарезервирует 16384 Мб оперативной памяти, но для использования хост-системой эта память будет недоступна, её сможет использовать только виртуальная машина.
По итогу выбор между динамичными и статичными большими страницами должен опираться на конкретный сценарий использования.
На этом завершается разбор основных вариантов оптимизации работы виртуальных машин с упором на виртуализацию ОС Windows 10.